Кодировщики голоса (Vocoder)
Вокодер, или кодировщик голоса, – это технологическое новшество, которое активно применяется в различных сферах связи, включая военные системы, диспетчерские службы и системы пейджерной связи. Создатели этой технологии уделили особое внимание механизмам работы человеческого речевого аппарата – горла, голосовых связок и другим компонентам. Так, например, звонкие и глухие звуки кодируются различными методами, используя в одних случаях импульсный генератор, в других – генератор шума.
Чтобы лучше понять принцип работы вокодера, можно обратить внимание на блок-схему, представленную на рисунке 2.4.2.1. Основная идея заключается в разделении исходного спектра человеческого голоса на субдиапазоны. В рассматриваемой модели их число достигает 16, при этом каждый субдиапазон имеет ширину в 200 Гц. Для обработки этих субдиапазонов используются узкополосные фильтры. После этого сигналы проходят через выпрямители и фильтры низких частот (20 Гц). Затем эти сигналы подвергаются мультиплексированию и дальнейшему преобразованию в цифровую форму. Процесс стробирования этих сигналов происходит с частотой около 50 Гц, при этом разрядность аналого-цифрового преобразователя может достигать 3 бита.
На принимающей стороне происходит обратный процесс: цифровой сигнал преобразуется в аналоговый (ЦАП), затем осуществляется мультиплексирование. Сбалансированные амплитудные модуляторы, управляемые данным ЦАП и специальным переключателем, направляют сигналы на соответствующие узкополосные фильтры. После этого все полученные сигналы комбинируются в сумматоре, и итоговый результат воспроизводится для слушателя.
Из представленной схемы видно, что для обеспечения передачи данных по такому каналу с необходимым быстродействием, требуется пропускная способность равная 2,4 Кбит/с (рассчитано на основе формулы: 3 бита * 50 Гц * 16 каналов). Однако, благодаря дополнительным методам цифрового сжатия, этот показатель может быть оптимизирован. В зависимости от задач и потребностей, можно варьировать число каналов (фильтров) и ширину полосы частот, что, в свою очередь, будет влиять на качество воспроизведения звука. Интересно отметить, что минимально возможная пропускная способность канала, при которой речь все еще воспринимается корректно, может быть менее 1 Кбит/с.
Рассмотрим простой пример. Представим фразу длиной примерно в 150 символов, включая пробелы и знаки препинания. Для того чтобы произнести эту фразу, человеку потребуется около 10 секунд, исходя из средней скорости речи в 15 символов в секунду. Однако, если бы мы решили передать эту фразу с использованием вокодера, нам потребовалось бы передать минимум 10000 бит информации. Откуда такая разница? Причина в том, что речь человека уникальна. Одна и та же фраза, произнесенная разными людьми, звучит по-разному. Помимо этого, в речи присутствует эмоциональная окраска, которая отсутствует в письменной форме.
Современные системы сжатия аудиоданных, несмотря на их эффективность, все равно не идеальны. Есть множество путей для дальнейшего улучшения этих систем, и выбор конкретного метода будет зависеть от поставленной задачи. Например, если целью является только передача информационного содержания, то можно преобразовать аудио в текст, передать его в цифровой форме и затем преобразовать обратно в аудио на принимающей стороне. Но такой подход может ввести дополнительную задержку из-за процесса сжатия и декодирования.
Если же нам важно передать и индивидуальные особенности голоса, то необходимо предварительно проанализировать эти особенности и передать их в закодированном виде. Это потребует более мощного оборудования и, возможно, станет реальностью только в будущем.
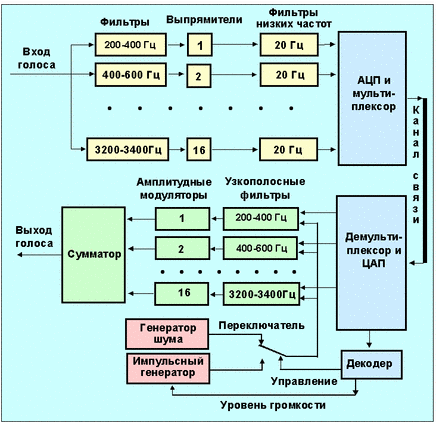
Рис. 2.4.2.1. Блок-схема кодирования/декодирования человеческого голоса (Vocoder)