Протокол MNP5
Протокол MNP 5 реализует комбинацию адаптивного кодирования с применением кода Хаффмена и группового кодирования. При этом хорошо поддающиеся сжатию данные уменьшают свой исходный объем примерно на 50% и, следовательно, реальная скорость их передачи возрастает вдвое по сравнению с номинальной скоростью передачи данных модемом.
На первом этапе процедуры сжатия используется метод группового кодирования для удаления из потока передаваемых данных слишком длинных последовательностей повторяющихся символов. Этот метод преобразует каждую группу из трех и более (вплоть до 253) одинаковых смежных символов к виду символ и число символов. Поскольку групповое кодирование не связано с большими вычислениями, этот метод особенно хорош для реализации в реальном масштабе времени, в частности, при передаче данных по линиям связи.
Согласно данного метода система группового кодирования проверяет проходящий поток данных. Алгоритм остается пассивным до тех пор, пока в этом потоке не обнаружатся три одинаковых смежных символа. После этого алгоритм начинает счет и удаляет из потока данных до 250 одинаковых следующих друг за другом символов. Счетный байт посылается вслед за тремя исходными символами, и передача продолжается. На рис. 8.2 показан пример группового кодирования потока данных.
Способность метода группового кодирования сжимать длинные последовательности очевидна. Тем не менее, рис. 8.2 иллюстрирует также одну из слабостей данного алгоритма. Кодирование группы из трех символов, наоборот, расширяет поток данных.
На втором этапе сжатия данных протокол MNP5 использует адаптивное кодирование на основе метода Хаффмена, известное также как адаптивное частотное кодирование. Этот способ кодирования основан на предположении,
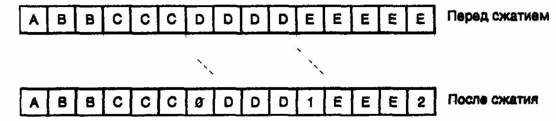
Рис. 8.2. Групповое кодирование по протоколу MNP5
что некоторые символы будут встречаться в потоке данных чаще, чем другие. Символы, которые встречаются чаще, кодируются с использованием небольшого числа битов. Реже встречающиеся символы передаются с использованием более длинных кодовых последовательностей.
Когда формат передаваемых данных относительно хорошо известен и постоянен, кодовые битовые последовательности, или лексемы, могут быть определены заранее. Однако адаптивный алгоритм может подстраиваться под поток данных путем "обучения" с последующим изменением своих лексем.
В протоколе MNP5 определяются 256 лексем для всех возможных 8-разрядных величин (октетов). Лексема состоит из 3-разрядного префикса (заголовка) и суффикса (тела, или основы), который может включать от 1 до 8 разрядов. Как передатчик, так и приемник инициализируют свои символьно-лексемные таблицы в соответствии с табл. 8.9. Первая и последняя записи
Таблица 8.9. Карта символьно-лексемного кодирования в начале процедуры уплотнения данных
| Значение октета (десятичное) | Заголовок лексемы | Тело лексемы |
0 | 000 | о |
1 | 000 | 1 |
2 | 001 | о |
3 | 001 | 1 |
4 | 010 | 00 |
5 | 010 | 01 |
6 | 010 | 10 |
7 | 010 | 11 |
8 | 011 | 00 |
15 | 011 | 111 |
16 | 100 | 0000 |
..'. | ||
31 | 100 | 1111 |
32 | 101 | 00000 |
. | ||
63 | 101 | 11111 |
64 | 110 | 000000 |
127 | 110 | 111111 |
128 | 111 | 0000000 |
254 | 111 | 1111110 |
255 | 111 | 11111110 |
(строки) этой таблицы содержат наиболее и наименее часто встречающиеся октеты, соответственно.
После того как обработан каждый октет, таблица переопределяется, исходя из частоты появления каждого символа. Октетам, которые появляются чаще всего, приписываются наиболее короткие лексемы. На приемном конце лексемы преобразуются в символы. В соответствии с частотой появления тех или иных символов трансформируется таблица приемника. Тем самым осуществляется самосинхронизация, таблиц кодирования и декодирования.