Протокол MNP7
Протокол MNP7 использует более эффективный (по сравнению с MNP5) алгоритм сжатия данных и позволяет достичь коэффициента сжатия порядка 3:1. MNP7 использует улучшенную форму кодирования методом Хаффмена в сочетании с марковским алгоритмом прогнозирования для создания кодовых последовательностей минимально возможной длины.
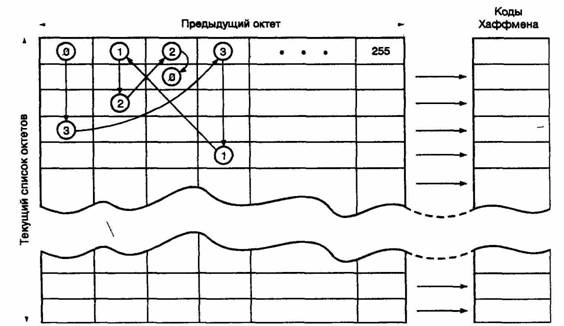
Рис. 8.3. Кодирование при помощи марковского алгоритма прогнозирования и кода Хаффмена
Марковский алгоритм может предсказывать следующий символ в последовательности, исходя из появившегося предыдущего символа. Для каждого ок-Teia формируется таблица из всех 256 возможных следующих за ним октетов, расположенных в соответствии с частотой их появления. Октет кодируется путем выбора столбца, соответствующего предыдущему октету (озаглавливающему столбец), с последующим отысканием в этом столбце значения текущего октета. Строка, в которой находится текущий октет, определяет лексему точно так же, как в описанном выше случае кодирования с использованием кода Хаффмена После того как каждый октет будет закодирован, порядок следования записей (октетов) в выбранном столбце изменяется в соответствии с новыми относительными частотами появления октетов.
На рис. 8.3 показан пример кодирования последовательности октетов 3120 в предположении, что перед этим был передан октет 0. Из рис. 8.3. видно, что в столбце, соответствующем предыдущему октету 0, отыскивается запись (строка) октета 3. После этого передается код Хаффмена для этой записи (октета 3) в таблице. Далее в столбце, соответствующем этому только что переданному октету 3, отыскивается строка с записью следующего октета — в данном случае октета 1, и передается код Хаффмена для этой строки и т.д. В этом примере отсутствует иллюстрация адаптивной части алгоритма, изменяющей порядок расположения октетов в каждом столбце.