Глава 14. Мониторинг и обслуживание Active Directory
Даже прекрасно разработанная, спланированная и реализованная инфраструктура Active Directory не будет оставаться в оптимальном состоянии без повседневного мониторинга и обслуживания. Active Directory представляет собой сложную распределенную сетевую службу, в больших организациях она будет подвержена тысячам изменений каждый день (создание или удаление учетных записей пользователя и их атрибутов, группового членства и разрешений). Для гарантии того, что эти изменения в сети и рабочей среде не будут отрицательно влиять на работу Active Directory, нужно ежедневно предпринимать профилактические действия. В этой главе исследуются два фундаментальных элемента поддержки инфраструктуры Active Directory: мониторинг контроллеров домена и обслуживание базы данных Active Directory.
Мониторинг Active Directory
Мониторинг состояния Active Directory необходим для поддержания надежного уровня службы каталога вашей организации. Ваши пользователи полагаются на эффективное функционирование службы каталога и считают само собой разумеющимся то, что они имеют возможность войти в сеть, обратиться к общедоступным ресурсам, получить и послать электронную почту. Их деятельность целиком зависит от здорового состояния и функциональности службы каталога Active Directory.
Отдельного инструмента или пакета программ, предназначенного для мониторинга Active Directory, не существует. Скорее мониторинг здорового состояния Active Directory является комбинацией задач, имеющих общую цель - измерение текущей характеристики некоторого ключевого индикатора (занимаемый объем диска, степень использования процессора, период работоспособного состояния службы и т.д.) по сравнению с известным состоянием (отправная точка). Поэтому ваш мониторинг службы каталога будет состоять из различных задач и инструме-нов. (Существуют наборы инструментов, которые могут соединить мониторинг этих ключевых индикаторов вместе в легко управляемый интерфейс, и для больших организаций наличие таких средств очень существенно, но они дороги, сложны и требуют много ресурсов.) В этой главе обсуждается, что именно вы должны отслеживать, и рассматриваются некоторые инструменты для этих целей, доступные в системе Microsoft Windows Server 2003. Вы сами можете решить, какие из этих инструментальных средств управления службой Active Directory удовлетворят ваши потребности.
Чтобы разбираться в мониторинге Active Directory, вы должны знать, почему его следует проводить, как это делать и что конкретно нужно отслеживать. Чтобы сохранить максимальную производительность службы каталога, необходимо также знать, что предпринимать в ответ на проведенный мониторинг. Цель этой главы состоит в том, чтобы вы могли делать все необходимое, что требуется для поддержания функционального состояния службы в пределах нормальных рабочих параметров, которые вы установили. Например, еслимониторинг функционирования службы показывает, что диск, на котором расположена база данных Active Directory, фрагментирован, вы должны его дефрагментировать.
Почему следует проводить мониторинг Active Directory?
Традиционная причина проведения мониторинга Active Directory состоит в том, что он идентифицирует потенциальные проблемы прежде, чем они проявятся и закончатся длительными периодами простоя службы. Мониторинг дает возможность поддерживать соглашение об уровне сервиса (service-level agreement - SLA) с вашим клиентом (пользователем сети). В любом случае вы должны следить за «здоровьем» Active Directory, чтобы разрешать возникающие проблемы как можно скорее, до того, как произойдет прерывание работы службы.
Примечание. Соглашение SLA - это контракт между провайдером услуг (вы) и сообществом пользователей, который определяет обязанности каждой из сторон и представляет обязательства, обеспечивающие определенную степень качества и количества уровню функционирования службы. В контексте Active Directory соглашение SLA между отделом информационных технологий (IT ) и сообществом пользователей может содержать такие параметры, как максимально приемлемый уровень времени простоя системы, время входа в систему и время получения ответа на справочный запрос. В обмен на обязательства провайдера услуг обеспечивать определенные стандарты производительности и функциональности системы, сообщество пользователей обязуется придерживаться определенных объемов использования системы, например, иметь не более 10000 пользователей в лесу Active Directory.
Еще одна причина для проведения мониторинга Active Directory состоит в том, что нужно отслеживать изменения инфраструктуры. Увеличился ли размер базы данных вашей Active Directory с прошлого года? Все ли ваши серверы глобального каталога (GC) работают в интерактивном режиме? Сколько времени требуется для того, чтобы изменения, сделанные на контроллере домена во Франции, были реплицированы на контроллер домена в Австралии? Возможно, эта информация не поможет вам предотвратить возникновение сегодняшней ошибки, но она обеспечит вас ценными данными, с которыми вы сможете строить планы на будущее.
Выгоды от мониторинга Active Directory
Выгоды, которые можно получить от проведения мониторинга Active Directory, включают следующее.
- Способность поддерживать SLA-соглашение с пользователями, избегая простоя службы.
- Достижение высокой производительности службы Active Directory путем устранения «узких мест» в работе, которые иначе нельзя обнаружить.
- Снижение административных затрат с помощью профилактических мер в обслуживании системы.
- Повышенная компетентность при масштабировании и планировании будущих изменений инфраструктуры в результате глубокого знания компонентов Active Directory, их функциональных возможностей и текущего уровня использования.
- Увеличение доброжелательности в отношении IT-отдела в результате удовлетворения клиентов.
Затраты на мониторинг Active Directory
Мониторинг инфраструктуры вашей службы Active Directory связан с затратами. Ниже перечислены некоторые затраты, необходимые для его эффективной реализации.
- Для проектирования, развертывания и управления системой мониторинга требуются человеко-часы.
- На приобретение необходимых средств управления, на обучение и на аппаратные средства, которые предназначены для реализации мониторинга, требуются определенные фонды.
- Часть пропускной способности вашей сети будет использоваться для мониторинга «здоровья» Active Directory на всех контроллерах домена предприятия.
- Для выполнения приложений-агентов на целевых серверах и на компьютере, являющемся центральным пультом мониторинга, используются память и ресурсы процессора.
Стоит отметить, что стоимость мониторинга быстро повышается, когда вы перемещаетесь на платформу глобального мониторинга предприятия типа Microsoft Operations Manager (MOM). Инструментальные средства MOM дороги, требуют обучения оператора и расходуют большее количество системных ресурсов в отличии от мониторинговых решений Windows Server 2003, но они являются проверенными, интегрированными и поддерживаемыми продуктами.
Уровень вашего мониторинга будет зависеть от результатов анализа выгод и затрат. В любом случае стоимость ресурсов, которые вы задействуете в системе мониторинга, не должна превышать ожидаемую от мониторинга экономию. По этой причине большие организации находят более рентабельным вкладывать капитал в комплексные решения по управлению предприятием. Для менее крупных организаций более оправдано использовать инструментальные средства мониторинга, встроенные в систему Windows Server 2003.
Дополнительная информация. MOM включает управление событиями, мониторинг служб и предупреждений, генерацию отчетов и анализ тенденций. Это делается через центральный пульт, в котором агенты, выполняющиеся на управляемых узлах (серверах, являющихся объектами мониторинга), посылают данные, которые будут проанализированы, отслежены и отображены на едином пульте управления. Эта централизация дает возможность сетевому администратору управлять большой совокупностью серверов из одного места с помощью мощных инструментов, предназначенных для удаленного управления серверами. Системы MOM используют пакеты управления для расширения базовой информации, касающейся определенных сетевых услуг, а также серверных приложений. Пакет управления Base Management Pack содержит характеристики всех служб сервера Windows Server 12003, включая Active Directory, службу доменных имен (DNS) и интернет-службу Microsoft Internet Information Services (IIS). Пакет управления Application Management Pack включает характеристики серверов Microsoft .NET Enterprise Servers, таких как Microsoft Exchange 2000 Server и Microsoft SQL Server 2000. Дополнительную информацию о MOM смотрите на сайте http://www.microsoft.com/mom.
Как осуществлять мониторинг Active Directory
Осуществляя мониторинг Active Directory, вы будете отслеживать ключевые индикаторы производительности и сравнивать их с базовыми показателями, которые представляют работу службы в пределах нормальных параметров. Когда индикатор работоспособности превышает указанный порог, выдается предупреждение, уведомляющее администрацию сети (или оператора мониторинга) о текущем состоянии системы. Предупреждение может также инициировать автоматические действия, направленные на решение проблемы или уменьшение дальнейшего ухудшения «здоровья » системы и т.де.
Ниже приводится схема процесса мониторинга службы Active Directory высокого уровня.
- Определите, какой из индикаторов функционирования службы вы должны отслеживать. (Начните с просмотра своих SLA-соглашений с клиентами.)
- Выполните мониторинг индикаторов функционирования службы, чтобы установить и задокументировать свой базовый уровень.
- Определите свой пороги для этих индикаторов функционирования. (Другими словами, определите, при каком уровне индикатора вы должны принимать меры, предотвращающие расстройство функционирования службы.)
- Спроектируйте необходимую аварийную систему, предназначенную для обработки событий достижения порогового уровня. Ваша аварийная система должна включать:
- уведомления оператора;
- автоматические действия, если они возможны;
- действия, инициируемые оператором.
- Спроектируйте систему создания отчета, фиксирующую историю системного «здоровья» Active Directory.
- Реализуйте свое решение, чтобы измерять выбранные ключевые индикаторы в соответствии с расписанием, отражающим изменения данных индикаторов и их воздействие на «здоровье» Active Directory.
Далее в разделе исследуется каждое из этих действий. Идентификация индикаторов функционирования описана в разделе «Что следует отслеживать».
Установление базовых уровней и порогов
После определения индикаторов функционирования, которые следует подвергнуть мониторингу, нужно собрать базовые данные для этих индикаторов. Базовый уровень представляет собой уровень индикатора функционирования, соответствующий пределам нормальной работы системы. Пределы нормальной работы должны включать и низкие, и высокие значения, которые ожидаются для определенного счетчика. Чтобы точнее фиксировать базовые данные, вы должны собирать информацию о работе системы в течение достаточно длительного периода времени, чтобы отразить диапазон значений. Например, если вам требуется установить базовый уровень производительности для аутентификационных запросов, убедитесь, что вы отслеживали значения этого индикатора в те периоды времени, когда большинство ваших пользователей входит в систему.
При определении своих базовых значений документируйте эту информацию и дату создания данной версии документа. В дополнение к тому, что эти значения используются для установки порогов, через какое-то время они будут полезны для определения тенденций в функционировании системы. Для документирования хорошо подходит таблица со столбцами, содержащими низкое, среднее и высокое значения для каждого счетчика, а также пороги для предупреждений.
Совет.Когда изменяется среда вашей службы Active Directory (например, если увеличивается количество пользователей или производится изменение аппаратуры на контроллерах домена), установите заново свои базовые значения. Базовые значения должны всегда отражать самое современное состояние Active Directory, выполняющейся в пределах нормы. Устаревшие базовые значения бесполезны для анализа текущих данных о фун-кционировании системы.
После того как вы определили базовые значения, определите пороговые значения, которые должны вызывать предупреждения. Кроме рекомендаций, сделанных компанией Microsoft, не существует никакой волшебной формулы для этого. Основываясь на инфраструктуре вашей сети, вы должны определить, какое значение счетчика указывает на то, что тенденция в функционировании службы направлена на прекращение ее работы. При установлении своих порогов для начала будьте консервативны. (Используйте или значения, рекомендуемые Microsoft, или даже более низкие значения.) В результате вам придется обрабатывать большое количество предупреждений. По мере того как вы соберете больше данных о счетчике, вы сможете поднять порог для уменьшения количества предупреждений. Этот процесс может занимать несколько месяцев, но, в конечном счете, вы настроите свою реализацию службы Active Directory.
Счетчики производительности и пороги
Следующие таблицы перечисляют ключевые счетчики производительности и пороговые значения, которые полезны для мониторинга Active Directory, в соответствии с рекомендациями компании Microsoft. Имейте в виду, что среда каждого предприятия будет иметь свои уникальные характеристики, которые влияют на применимость этих значений. Считайте эти пороги отправной точкой и с помощью описанного ранее мониторинга уточните, чтобы они отражали особенности вашей среды.
Производительность Active Directory
Счетчики производительности (см. табл. 14-1) выполняют мониторинг основных функций и служб Active Directory. Если не указано другого, пороги определяются в результате мониторинга базовых значений. Чтобы получить доступ к этим счетчикам, откройте Start (Пуск) >Administrative
Tools (Средства администрирования)>Регfоmance(Производительность), а затем щелкните на кнопке Add (Добавить) над диаграммой. Разделы, данные после этой таблицы, описывают установку свойств счетчика.
Табл. 14-1. ОсновныефункцииислужбыActiveDirectory
Объект | Счетчик | Интервал | Почему этот счетчик важен |
NTDS | DS Search sub-operations/sec (DS поисковые подоперации/секунда) | Каждые 15 минут | Запросы на поиск поддеревьев очень интенсивно используют ресурсы системы. Любое его увеличение может указывать на проблемы с производительностью контроллера домена. Проверяйте, происходят ли случаи неправильного обращения приложений к контроллеру домена. |
Процесс | % Processor Time(Instance=lsass) (% времени процессора) | Каждую минуту | Указывает процент от времени процессора, используемого службой Active Directory. |
NTDS | LDAP Searches/ sec (LDAP поиск/ секунда) | Каждые 15 минут | Является хорошим индикатором объема использования контроллера домена. В идеале он должен иметь одинаковые значения для всех контроллеров домена. Увеличение значения указывает на то, что новое приложение обращается к этому контроллеру домена, или что больше клиентов было добавлено к сети. |
NTDS | LDAP Client Sessions (LDAP сеансы клиентов) | Каждые 5 минут | Указывает текущее количество клиентов, связанных с контроллером домена. Его увеличение указывает на то, что другие машины не выполняют свою работу, перегружая этот контроллер домена. Обеспечивает полезной информацией о том, в какое время дня пользователи преимущественно выходят в сеть, и максимальном числе клиентов, связывающихся с сетью каждый день. |
Процесс | Private Bytes (Instance=lsass) (Личные байты) | Каждые 15 минут | Отслеживает объем памяти, используемой контроллерами домена. Непрерывный рост значения указывает на увеличение потребности рабочей станции за счет поведения приложений (оставляют дескрипторы) или на увеличение числа рабочих станций, обращающихся к контроллеру домена. При значительном отклонении значения этого счетчика от нормального значения, соблюдаемого на других, равных по положению, контроллерах домена, вы должны исследовать причину этого. |
Процесс | Handle Count (Instance=lsass) Счетчик дескрипторов) | Каждые 15 минут | Полезен для обнаружения плохого поведения приложения, не закрывающего дескрипторы должным образом. Значение этого счетчика увеличивается линейно по мере добавления клиентских рабочих станций. |
Процесс | Virtual Bytes (Instance=lsass) (Виртуальные байты) | Каждые 15 минут | Используется для определения того, что Active Directory выполняется при нехватке виртуального адресного пространства памяти, что называет на утечку памяти. Убедитесь, что у вас выполняется самый последний сервисный пакет (service pack), и наметьте перезагрузку на ближайшие нерабочие часы, чтобы избежать простоя системы. Этот счетчик может использоваться для определения того, что остаются доступными менее 2-х гигабайт виртуальной памяти. |
Счетчики, характеризующие функционирование репликации
Счетчики (см. табл. 14-2) отслеживают количество реплицируемых данных. Пороги определяются по базовым значениям, установленным ранее, если не указано ничего другого.
Табл. 14-2. Счетчики, характеризующиерепликацию
Объект | Счетчик | Рекомендуемый интервал | Почему этот счетчик важен |
NTDS | DRA Inbound Bytes Compressed (DRA входящие сжатые байты) (Между сайтами после сжатия/ секунды) | Каждые 15 минут | Указывает количество репли-цируемых данных, входящих в этот сайт. Изменение значения этого счетчика указывает на изменение топологии репликации или на то, что существенные данные были добавлены или изменены в Active Directory. |
NTDS | DRA Outbound Bytes Compressed (DRA исходящие сжатые байты) (Между сайтами после сжатия/ секунды) | Каждые 15 минут | Указывает количество реплици-руемых данных, выходящих из этого сайта. Изменение значения этого счетчика указывает на изменение топологии ответа или на то, что существенные данные были добавлены или изменены в Active Directory. |
NTDS | DRA Outbound Bytes Not Compressed (Исходящие несжатые DRA байты ) | Каждые 15 минут | Указывает количество репли-цируемых данных, выходящих из этого контроллера домена, но адресованных в пределах сайта. |
NTDS | DRA Outbound Bytes Total/sec (Общее количество исходящих DRA байтов/ секунда) | Каждые 15 минут | Указывает количество реплици-руемых данных, выходящих из этого контроллера домена. Изменение значения этого счетчика указывает на изменение топологии репликации или на то, что существенные данные были добавлены или изменены в Active Directory. Это важный счетчик, который следует отслеживать. |
Работа подсистемы защиты
Счетчики (см. табл. 14-3) отслеживают ключевые объемы, связанные с защитой. Пороги определены в результате мониторинга базовых значений, если не указано другого.
Табл. 14-3. Ключевыеобъемы, связанныесзащитой
Объект | Счетчик | Рекомендуемый интервал | Почему этот счетчик важен |
NTDS | NTLM Authentications (NTLM аутентификации) | Каждые 15 минут | Указывает количество клиентов в секунду, которые аутенти-фицируются на контроллере домена, используя NTLM вместо Kerberos (клиенты, имеющие более ранние, чем Windows 2000, системы или аутентификация между лесами). |
NTDS | KDC AS Requests (Запросы KDC AS) | Каждые 15 минут | Указывает количество билетов сеанса, выпускаемых в секунду центром распределения ключей (KDC). Позволяет наблюдать воздействие изменения срока службы билета. |
NTDS | Kerberos Authentications (Аутентификации Kerberos) | Каждые 15 минут | Указывает количество нагрузки, связанной с аутентификацией, получаемой центром KDC. Позволяет наблюдать тенденции роста. |
NTDS | KDC TGS Requests (Запросы KDC TGS) | Каждые 15 минут | Указывает количество TGT билетов, выпускаемых службой KDC. Используется для наблюдения за изменением срока службы билета. |
Функционирование ядра операционной системы
Счетчики (см. табл. 14-4) отслеживают индикаторы, характеризующие работу ядра операционной системы, они прямо воздействуют на производительность Active Directory.
Табл. 14-4. Основныеиндикаторыоперационнойсистемы
Объект | Счетчик | Интервал | Порог | Значимость превышения порогового значения |
Memory (Память) | Page Faults/ sec (Ошибки страницы/ секунды) | Каждые 5 минут | 700/с | Высокая степень ошибок страницы указывает на недостаточную физическую память. |
Physical Disk (Диск) | Current DiskQueue «length (Текущая длина очереди к Диску) | Каждую | Удвоенное среднее значение в течение трех интервалов | Отслеживает объемы файлов Ntds.dit и .log. Указывает, что имеется отставание дисковых запросов ввода/ вывода. Рассмотрите возможность увеличения диска и производительности контроллера. |
Processor (Процессор) | % DPC Time (Instance=_Total) (% времени DPC) | Каждые 15 минут | 10 | Указывает отложенную работу, из-за занятости контроллера домена. Превышение порогового значения указывает на возможную перегрузку процессора. |
System (Система) | Processor Queue Length (Длина очереди к процессо-РУ) | Каждую минуту | Шесть | Процессор недостаточно быстр, чтобы обрабатывать запросы по мере их поступления. Если топология репликации правильна, и данное состояние не вызвано отказами другого контроллера домена, рассмотрите возможность обновления процессора. | |
Memory (Память) | Available MBytes (Доступные мегабайты) | Каждые 15 минут | 4 Мб | Указывает, что система исчерпала доступную память. Вероятен надвигающийся отказ в работе службы. | |
Processor (Процессор) | % Processor Time (Instance=_Total) (% времени процесора) | Каждую минуту | 85 % от следнего значения в течение трех интервалов | Указывает на перегрузку центрального процессора. Определите, вызвана ли перегрузка процессора службой Active Directory, исследуя объект Process, счетчик % Processor Time, Isass instance. | |
System (Система) | Context Switches/sec (Переключение контекста/ секунда) | Каждые 15 минут | 70000 | Указывает на чрезмерное количество переходов. Возможно, что работает слишком много приложений шщ служб, или их нагрузка на систему слишком высока. Рассмотрите возможность разгрузки системы от части этих требований. | |
System (Система) | System Up Time (Время работы системы) | Каждые 15 минут | Важный счетчик, показывающий надежность контроллера домена. | ||
Предостережение.Приведенные выше значения основаны на пороговых значениях, которые были рекомендованы компанией Microsoft на момент печати этой книги, и должны рассматриваться как предварительные значения. Информация содержится в руководстве Directory Services Guide комплекта Microsoft Windows Server 2003 Resource Kit. Свежую информацию о выпуске комплекта ресурсов смотрите по адресу http:// www.microsoft.com/windowsserver2003/techinfo/reskit/reso urcekit.mspx.
Проектирование предупреждений
Предупреждение определяется как уведомление, которое вызывается автоматически, когда значение счетчика достигает порогового уровня. Используя инструмент администрирования Performance, имеющийся в системе Windows Server 2003, вы может сконфигурировать предупреждение для любого доступного счетчика функционирования системы.
Примечание. Когда Active Directory Installation Wizard устанавливает Active Directory, он конфигурирует счетчики функциональности в объекте NTDS Performance, который обеспечивает статистику деятельности службы каталога. Эти счетчики применимы ко всему каталогу, включая глобальные каталоги GC.
Счетчики функционирования базы данных Active Directory для базы данных ESENT (Ntds.dit) не устанавливаются во время инсталляции Active Directory. Вы должны добавить их вручную. Чтобы найти автоматизированный сценарий, который устанавливает счетчики функционирования базы данных Active Directory, смотрите статью Install Active Directory Database Performance Counters (Установка счетчиков функционирования базы данных Active Directory) в Центре сценариев Microsoft по адресу http://www.microsoft.com/technet/treeview/default.asp? url —/technet/scriptcenter /monitor/ScrMonO8.asp. Вы можете скопировать этот сценарий в текстовой файл, дать файлу свое название и расширение .vbs, а затем выполнить его для установки счетчиков функционирования базы данных ESENT.
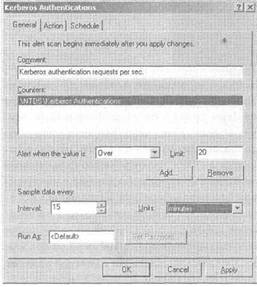
Чтобы создать предупреждение по поводу превышения числа аутен-тификационных запросов протокола Kerberos (порог равен 20-ти запросам в секунду) на контроллере домена, выполните следующие шаги.
- Откройте Performance (Производительность) в папке Administrative Tools (Средства администрирования).
- Дважды щелкните на Performance Logs And Alerts (Журналы работы и предупреждения), а затем щелкните на Alerts (Предупреждения).
- Из меню Action (Действия) выберите New Alert Settings (Параметры настройки новых предупреждений).
- В поле Name (Имя) напечатайте название предупреждения, а затем щелкните на кнопке ОК. Это название будет показано в контейнере Performance Logs And Alerts, поэтому используйте такое имя, которое определяет отслеживаемый счетчик.
- На вкладке General (Общее) дайте комментарий к вашему предупреждению, а затем щелкните на кнопке ADD (Добавить), чтобы добавить необходимый объект Performance и счетчики (см. рис. 14-1).

Рис. 14-1. Добавление счетчика к новому предупреждению- Введите пороговый предел, запускающий предупреждение. Установите интервал времени для выборки данных функционирования службы (см. рис. 14-2).
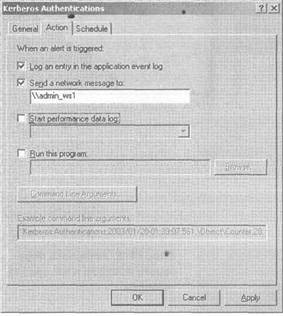
Рис. 14-2. Установка порогового предела и интервала выборки- На вкладке Action (Действия) определите события, которые должны происходить, когда значение счетчика достигнет порогового значения. Чтобы определить время, когда служба должна начать просматривать предупреждения, используйте вкладку Schedule (Расписание). Вкладка Action показывает, что предупреждение может вызвать несколько действий, включая следующие (см. рис. 14-3):
- создание записи в прикладном журнале регистрации событий;
- генерирование предупреждающего сообщения. Это сообщение может быть послано или по IP- адресу или на имя компьютера;
- запуск регистрации характеристик функционирования службы;
- выполнение программы.
Рис. 14-3. Определение действий, запускаемых новым предупреждениемВ дополнение к опциям, указанным на вкладке Actions, для эффективного мониторинга желательно иметь готовый план действий в ответ на предупреждение. После того как вы определите ваши счетчики, а также базовые и пороговые значения, обязательно задокументируйте корректирующие действия, которые вы предпримите для того, чтобы вернуть индикатор в пределы нормы. Они могут включать поиск неисправностей (например, возвращение контроллера домена в интерактивный режим) или передачу роли хозяина операций. Если ваша система достигла своих максимальных возможностей, возможно, для исправления текущего состояния придется добавить дополнительное дисковое пространство или память. Другие предупреждения потребуют от вас выполнения действий по обслуживанию Active Directory, таких как деф-рагментация файла базы данных Active Directory. Эти ситуации обсуж даются далее в этой главе в разделе «Автономная дефрагментация базы данных Active Directory».
Отслеживание «здоровой» функциональности сервера с помощью системного монитора
Инструмент System Monitor (Системный монитор) включен в средства администрирования Performance. Используя этот инструмент, можно собирать и рассматривать в реальном масштабе времени данные функционирования местного компьютера или нескольких удаленных компьютеров. Системный монитор дает графическое представление тех же самых данных, которые отслеживаются с помощью инструмента Performance Logs And Alerts. Этот инструмент значительно облегчает определение тенденций в работе службы.
Ниже перечислены три счетчика функционирования, заданных по умолчанию в системном мониторе.- Memory\Pages/sec (Память\Страницы/с).
- PhysicalDisk (_Total)\Avg. Disk Queue Length (Физический диск (__Тotа1)\средняя длина очереди к диску).
- Processor (_Total)\%Processor Time (Процессор (_Totа1)\Время процессора).
- Щелкните правой кнопкой мыши на панели деталей системного монитора, затем щелкните на Add Counters (Добавить компьютеры).
- В диалоговом окне Add Counters щелкните на Use Local Computer Counters (Счетчики локального компьютера пользователя), чтобы отслеживать работу компьютера, на котором выполняется консоль мониторинга. Чтобы отслеживать работу определенного компьютера независимо от того, где выполняется консоль мониторинга, щелкните на Select Counters From Computer (Выбрать счетчик на компьютере) и укажите имя компьютера или его IP-адрес.
- Выберите нужный объект Performance, а затем щелкните на счетчике, который вы хотите добавить. Здесь используется тот же самый интерфейс, который использовался для добавления счетчиков к новому предупреждению, описанный ранее.
- Щелкните на кнопке Add (Добавить), а затем щелкните на Close (Закрыть).
- Applicationlog(Журнал приложений). Содержит события, зарегистрированные приложениями или программами.
- Systemlog(Системный журнал). Содержит правомерные и неправомерные попытки входа в систему, а также события, связанные с использованием ресурсов, такие как создание, открытие и удаление файлов или других объектов.
- Securitylog(Журнал безопасности). Содержит события, зарегистрированные компонентами системы Windows.
- DirectoryServicelog(Журнал регистрации службы каталога). Содержит события, зарегистрированные службой Active Directory.
- FileReplicationServicelog(Журнал регистрации службы репликации файлов) Содержит события, зарегистрированные службой репликации файлов.
- DNSServerlog(Журнал сервера DNS). Содержит события, зарегистрированные службой сервера DNS.
- Репликация ActiveDirectory. Функционирование репликации существенно для обеспечения сохранности данных в пределах домена.
- Службы ActiveDirectory. Эти индикаторы функционирования отслеживаются с помощью счетчиков NTDS в инструменте администрирования Performance.
- Хранилище базы данных ActiveDirectory. Дисковые тома, которые содержат файл базы данных Active Directory Ntds.dit и файлы журналов .log, должны иметь достаточно свободного пространства, чтобы допускать нормальный рост и функционирование.
- Функционирование службы DNSи «здоровье» сервера. Поскольку Active Directory полагается на DNS при поиске ресурсов в сети, то сервер DNS и сама служба должны работать в нормальных пределах, чтобы Active Directory удовлетворяла заданному уровню качества обслуживания.
- Службарепликациифайлов(File Replication Service - FRS). Служба FRS должна работать в пределах нормы, чтобы гарантировать, что общий системный том (Sysvol) реплицируется по всему домену.
- «Здоровье» системы контроллера домена. Мониторинг этой области должен охватывать все аспекты здоровья сервера, включая счетчики, характеризующие использование памяти, процессора и разбиение на страницы.
- «Здоровье» леса. Эта область должна отслеживаться для того, чтобы проверить доверительные отношения и доступность сайта.
- Хозяева операций. Отслеживайте каждого хозяина операций FSMO, чтобы гарантировать «здоровье» сервера. Кроме того, проводите мониторинг для обеспечения доступности GC-каталога, позволяющего пользователям входить в систему и поддерживать членство универсальных групп.
- Событие ID1311. Информация о конфигурации репликации, имеющаяся в инструменте Active Directory Sites And Services (Сайты и службы Active Directory), не отражает точно физическую топологию сети. Эта ошибка указывает на то, что один или более контроллеров домена или сервер-плацдарм (bridgehead) находятся в автономном режиме, или что серверы-пладармы не содержат нужных контекстов именования (NC).
- Событие ID1265 (Access denied — Доступ запрещен). Эта ошибка может возникать в том случае, если локальный контроллер домена не сумел подтвердить подлинность своего партнера по репликации при создании репликационной связи или при попытке реплицировать по существующей связи, она возникает тогда, когда контроллер домена был отсоединен от остальной части сети в течение долгого времени, и его пароль учетной записи компьютера не синхронизирован с паролем учетной записи компьютера, хранящимся в каталоге его партнера по репликации.
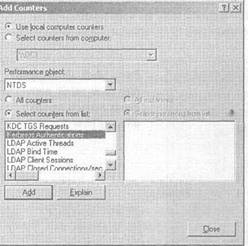
Примечание. Слева от обратной наклонной черты находится объектом функционирования, в круглых скобках дан экземпляр объекта (если имеется). Счетчик указан справа от наклонной черты.
Каждый из этих счетчиков показан в системе координат «время/работа» линией своего цвета. Они очень полезны для мониторинга системного «здоровья» сервера (в данном случае контроллера домена). На рисунке 14-4 показано заданное по умолчанию представление системного монитора.
Вы можете сконфигурировать несколько полезных опции для системного монитора.
Чтобы оптимизировать представление определенного счетчика, выберите описание счетчика, расположенное в нижней части окна, и щелкните на кнопке Highlight (Выделить) на инструментальной панели. Так вы измените график, соответствующий выбранному счетчику, представив его полужирной белой линией, чтобы его было легче рассматривать.
Вы можете переключаться между такими представлениями данных, как график, гистограмма и отчет, выбирая соответствующую кнопку на инструментальной панели.
Можно сохранить параметры настройки графика системного монитора в виде HTML-страницы. Для этого сконфигурируйте график необходимыми счетчиками, щелкните правой кнопкой мыши на графике и выберите Save As (Сохранить как). График будет сохранен в виде файла HTML, который вы сможете открыть в браузере. Когда вы открываете
HTML-версию графика, дисплей замораживается. Чтобы перезапустить мониторинг, щелкните на кнопке Freeze Display, расположенной на инструментальной панели Performance в браузере.
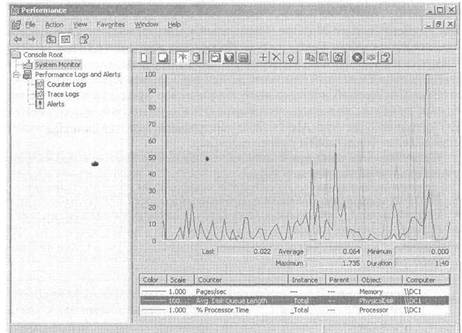
Рис. 14-4. Счетчики функционирования, заданные по умолчанию в системном мониторе
Вы можете импортировать сохраненный график назад в системный монитор, перемещая файл HTML в окно System Monitor. Этот способ удобен для сохранения и перезагрузки часто используемых графиков функционирования службы.
В системе Windows Server 2003 имеются две новые группы безопасности, которые гарантируют, что только надежные пользователи могут получить доступ и управлять данными функционирования службы: группы Performance Log Users (Пользователи, регистрирующие работу) и Performance Monitor Users (Пользователи, выполняющие мониторинг).
Чтобы добавить дополнительные счетчики к системному монитору, выполните следующие действия.
Мониторинг Active Directory с помощью инструмента Event Viewer
В дополнение к использованию инструмента Performance для мониторинга Active Directory вы должны периодически рассматривать содержимое журналов регистрации событий, используя инструмент администрирования Event Viewer (Средство просмотра событий). По умолчанию средство просмотра событий отображает следующие три регистрационных журнала.
Для серверов, сконфигурированных как контроллеры домена, на которых выполняется система Windows Server 2003, будут отображаться следующие журналы регистрации событий.
Если контроллер домена с системой Windows Server 2003 является также сервером DNS, то будет отображаться следующий журнал регистрации.
Для просмотра журнала регистрации событий выберите инструмент Event Viewer из папки Administrative Tools. Выберите журнал регист-
рации событий, предназначенный для той службы, работу которой вы хотите отслеживать. Левая область окна на рисунке 14-5 показывает все журналы событий для контроллеров домена с системой Windows Server 2003, которые являются также серверами DNS.
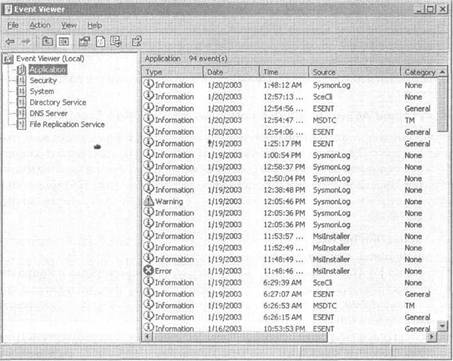
Рис. 14-5. Инструмент администрирования Event Viewer с журналами регистрации событий
В журнале регистрации событий рассмотрите типы событий Errors (Ошибки) и Warnings (Предупреждения). Чтобы отобразить детали событий в журнале регистрации, дважды щелкните на этом событии. На рисунке 14-6 показаны детали события Warnings (ID-событие 13562) из журнала File Replication Service (Служба репликации файлов).
Что следует отслеживать
Для мониторинга общего системного «здоровья» Active Directory нужно отслеживать работу, связанную со службой, и индикаторы функционирования, связанные с сервером, а также события. Вы должны гарантировать, что Active Directory и контроллеры домена, на которых она выполняется, работают в оптимальном режиме. При проектировании своей системы мониторинга планируйте наблюдение за следующими областями работы.
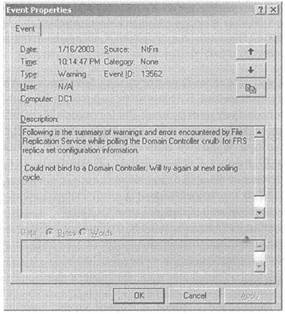
Рис. 14-6. Окно Event Properties (Свойства событий) для записи в журнал событий
Мониторинг репликации
Один из критических компонентов Active Directory, за работой которого вы должны наблюдать, - это репликация. В отличие от мониторинга контроллера домена, который использует инструмент Performance Monitor, репликация между контроллерами домена чаще всего отслеживается с помощью инструмента из набора Windows Server 2003 Support Tools (Средства обслуживания Windows Server 2003): Repadmin.exe, Dcdiag.exe и журнала регистрации событий службы каталога (см. выше). Repadmin представляет собой инструмент командной строки, который сообщает об отказах репликационных связей между двумя партнерами по репликации. Следующая команда вызывает отображение партнеров по репликации и все отказы репликационных связей для контроллера домена DC1, расположенного в домене Contoso.com:
repadmin/showreps dd .contoso.com
Dcdiag - это инструмент командной строки, который может проверять DNS-регистрацию контроллера домена. Он отслеживает наличие идентификаторов защиты (SID) в заголовках контекста именования (naming context) соответствующие разрешения для репликации, анализирует состояние контроллеров домена в лесе или предприятии и многое другое. Для получения полного списка опций Dcdiag напечатайте dcdiag/?. С помощью следующей команды можно проверить наличие ошибок репликации между контроллерами домена:
dcdiag/test: replications
И, наконец, журнал службы каталога сообщает об ошибках репликации, которые происходят после установления репликационной связи. Нужно просматривать журнал регистрации событий службы каталога в поисках событий репликации, имеющих тип Error (Ошибка) или Warning (Предупреждение). Далее приводится два примера типичных ошибок репликации в том виде, как они отображены в журнале регистрации событий службы каталога.